

Caídas y lentitud en servidores cloud no aparecen “de la nada”; por el contrario, casi siempre son el resultado de una cadena de decisiones técnicas y operativas que, con el tiempo, se vuelven fricción: recursos insuficientes, almacenamiento saturado, falta de monitoreo, parches acumulados, o respaldos que existen “en teoría” pero no en práctica. Por lo tanto, si hoy tu sistema se siente inestable, no necesitas adivinar: necesitas un método.
Además, el problema rara vez se limita a “la nube” como concepto. De hecho, el fallo suele estar en algo más específico: una VM mal dimensionada, un disco con IOPS limitadas, una red con jitter, o un servidor Windows sin ajustes para carga real. En consecuencia, en lugar de perseguir síntomas, conviene analizar capas: aplicación, base de datos, sistema operativo e infraestructura. Así reduces costo operativo y, al mismo tiempo, aumentas disponibilidad.
Señales tempranas de degradación que casi nadie toma en serio
Aunque a veces el equipo lo normaliza, una operación estable no debería depender de “reiniciar y listo”. Por eso, antes de hablar de soluciones, identifica señales concretas:
-
Lentitud intermitente a ciertas horas (picos de CPU, RAM o disco).
-
Pantallas que “se congelan” al guardar, timbrar o actualizar inventario.
-
Sesiones remotas que se desconectan con frecuencia.
-
Errores 5xx, timeouts, o servicios que se reinician solos.
-
Backups que tardan más cada semana, o que ya no caben en la ventana nocturna.
Aun así, no todas las señales apuntan al mismo origen. Sin embargo, sí comparten algo: cuando aparecen, ya existe un cuello de botella. Por lo tanto, el objetivo real es ubicar el cuello y eliminarlo sin romper lo que ya funciona.
Diagnóstico por capas: cómo encontrar el cuello en menos de 60 minutos
Para no perderte, trabaja de arriba hacia abajo:
1) Capa de aplicación (sistema/ERP):
Primero valida si la lentitud coincide con tareas específicas: timbrado, consultas, reportes, cierres de mes, conciliaciones, o cargas masivas. Luego, revisa si hay módulos nuevos, integraciones, o cambios recientes. Además, si el sistema es multiusuario, compara un usuario “rápido” contra uno “lento” para detectar si el problema es general o por perfil/datos.
2) Base de datos:
Después, revisa tamaño, crecimiento y mantenimiento: índices, fragmentación, jobs, y estadísticas. Aun cuando el proveedor del sistema diga “es normal”, una base sin mantenimiento amplifica cualquier limitación de disco. En consecuencia, la degradación suele parecer “misteriosa”, aunque sea totalmente medible.
3) Sistema operativo (Windows/Linux):
Posteriormente valida servicios, logs y consumo real. En Windows, por ejemplo, es común ver presión en disco por antivirus mal configurado, paginación agresiva, o servicios innecesarios. Por lo tanto, antes de “subir CPU”, revisa por qué se está consumiendo.
4) Infraestructura (VPS/Cloud):
Finalmente, confirma límites del plan: vCPU reales, RAM garantizada, almacenamiento (tipo, IOPS), red, y si existe oversubscription. Además, cuestiona el “hasta” del proveedor: “hasta X vCPU” no es lo mismo que recursos garantizados.
Si quieres una guía rápida para costos reales y qué incluye cada nivel, te conviene revisar Cuánto cuesta realmente un servidor para ERP en México, porque así aterrizas expectativas antes de invertir.
Causas típicas y cómo se ven en métricas reales
Para atacar con precisión, vincula síntoma con métrica:
-
CPU alta sostenida: suele ser cálculo, procesos concurrentes o consultas pesadas. Sin embargo, también puede ser compresión, antivirus o indexaciones.
-
RAM al límite: provoca swapping/paginación; por lo tanto, aunque “CPU se vea bien”, el sistema se siente lento.
-
Disco con cola (queue length) alta o IOPS insuficientes: se nota en guardados lentos y consultas que se congelan. Además, suele empeorar con el crecimiento de la base.
-
Red inestable: causa desconexiones en RDP, sesiones remotas y servicios que “se caen” sin razón aparente.
En consecuencia, no basta con “más recursos”; necesitas el recurso correcto. Y, sobre todo, necesitas medir antes, durante y después.
Monitoreo que sí sirve: lo mínimo viable para operar con control
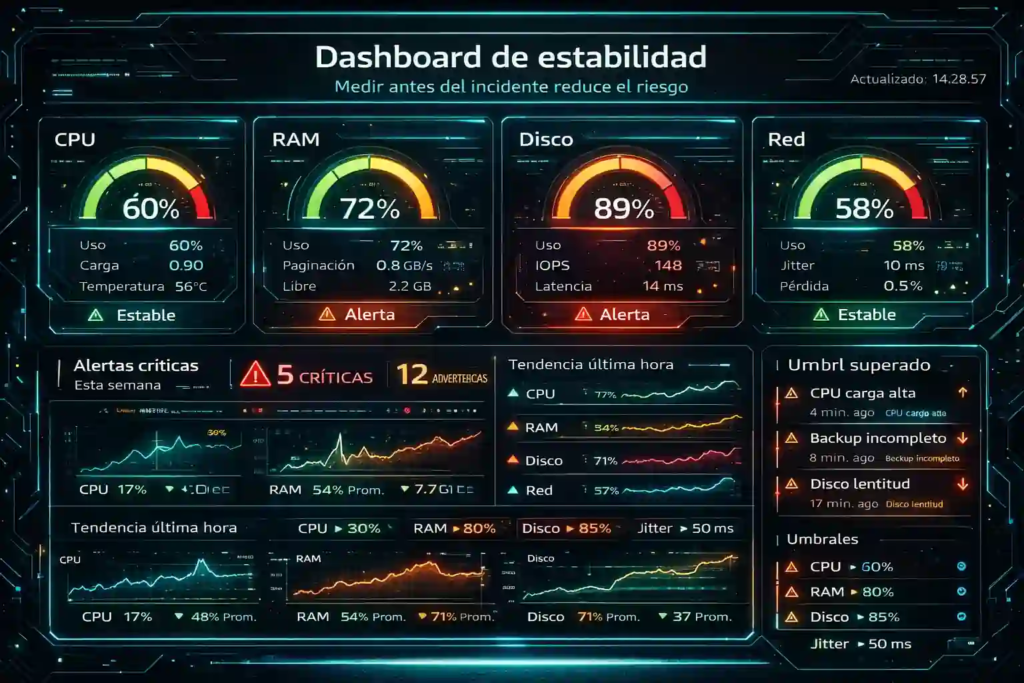
Si no hay monitoreo, todo se vuelve opinión. Por eso, arma un tablero con estos indicadores:
-
CPU: promedio, picos, y procesos top.
-
RAM: uso real, paginación, commits.
-
Disco: latencia, IOPS, throughput, espacio libre, y cola.
-
Red: latencia, pérdida de paquetes, jitter, retransmisiones.
-
Aplicación/DB: tiempos de consulta, bloqueos, errores, y jobs críticos.
Aquí aparece el punto clave: caídas y lentitud en servidores cloud se previenen más por disciplina operativa que por “comprar más”. Por lo tanto, si hoy no mides, mañana pagas doble: primero en horas-hombre, y luego en urgencias.
Además, cuando el monitoreo está bien, puedes definir umbrales y acciones: alertas, escalamiento, o ventanas de mantenimiento. En ese sentido, una operación madura es la que no se sorprende.
Si estás evaluando una base sólida para monitorear y escalar sin improvisación, revisa opciones de servidores virtuales cloud VPS orientados a carga empresarial.
Dimensionamiento correcto: no es “más grande”, es “más adecuado”
Una práctica común es “subir” CPU y listo. Sin embargo, si el cuello está en disco, subir CPU no cambia nada. Por eso, dimensiona en función de carga:
-
Número de usuarios concurrentes reales (no los que “podrían” conectarse).
-
Tamaño de base de datos hoy y proyección de crecimiento.
-
Ventanas de procesos pesados (cierres, reportes, timbrado, conciliación).
-
Integraciones (facturación, e-commerce, BI, bancos, APIs).
Además, define márgenes: si hoy operas a 70–80% en horas pico, estás a una caída de distancia. En consecuencia, apunta a operar con holgura, especialmente en disco y RAM.
Si sospechas que ya estás “al borde”, vale la pena contrastar síntomas con esta guía de señales: Señales de que tu servidor actual está en riesgo para ERP. Así decides con evidencia, no por corazonada.
Almacenamiento: el origen silencioso de la mayoría de incidentes
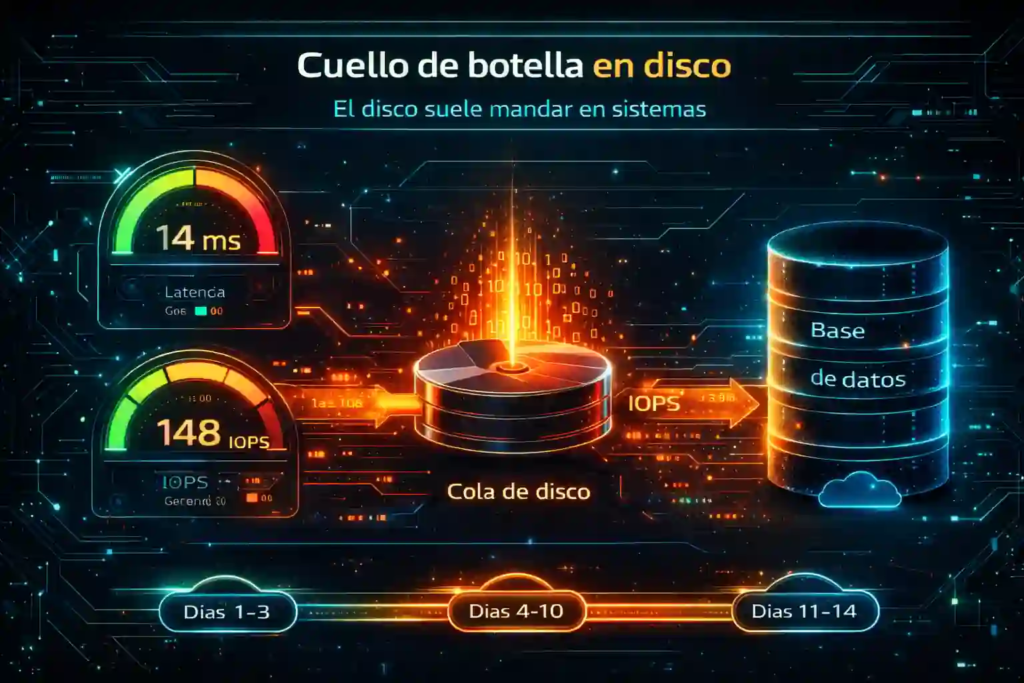
En sistemas administrativos, el disco manda más de lo que la gente cree. De hecho, un ERP puede “vivir” con CPU moderada, pero no con disco lento. Por lo tanto, revisa:
-
Tipo de almacenamiento (SSD, NVMe, premium, etc.).
-
IOPS garantizadas.
-
Latencia media y p95 (no solo “promedio”).
-
Separación de volúmenes (SO vs datos vs logs).
-
Estrategia de crecimiento (expandir sin apagar).
Cuando la base crece, la escritura de logs y la lectura de índices se vuelven constantes. En consecuencia, si tu almacenamiento no escala, la lentitud escala por ti.
Además, evita el error de “dejar 5–10% libre”. En servidores para sistemas, eso es receta para degradación. Mantén un margen razonable, y planifica expansiones con tiempo.
Red y acceso remoto: estabilidad también es rendimiento percibido
Aunque el servidor esté “bien”, una red inestable se siente como lentitud. Por eso, considera:
-
Rutas y saltos (traceroute) en horas pico.
-
Latencia desde sedes y home office.
-
Políticas de QoS si hay VPN o enlaces compartidos.
-
Configuración de RDP (compresión, recursos, límites de sesión).
Además, si tu operación depende de acceso remoto, la continuidad no se negocia: define redundancia, políticas de reconexión, y ventanas de mantenimiento visibles para usuarios. Así reduces tickets y estrés operativo.
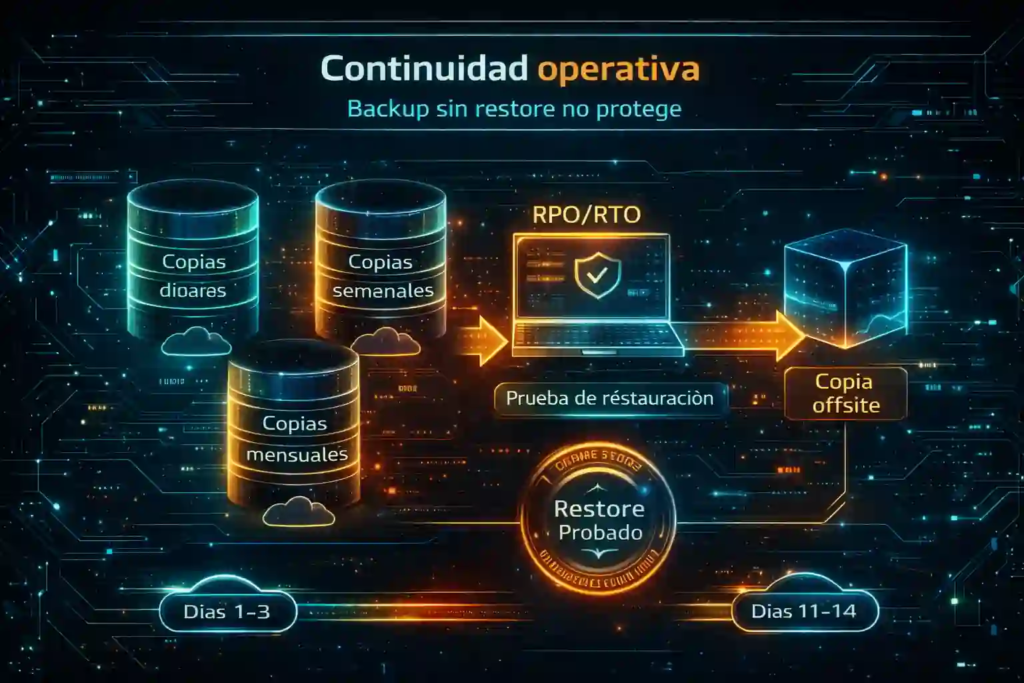
Backups y continuidad: el seguro que se prueba antes del siniestro
Aquí mucha gente falla: tiene “respaldo”, pero no tiene recuperación. Por lo tanto, tu estándar mínimo debería incluir:
-
Backups automáticos con retención (diaria, semanal, mensual).
-
Copia fuera del servidor (offsite) y, si aplica, inmutable.
-
Pruebas de restauración calendarizadas (no “cuando se pueda”).
-
RPO/RTO definidos (cuánta pérdida toleras, cuánto tardas en volver).
Si quieres aterrizarlo con prácticas claras, revisa Respaldos de equipos de cómputo en la nube, porque ahí se entiende la diferencia entre “tener archivos” y “tener continuidad”.
En este punto conviene decirlo sin rodeos: caídas y lentitud en servidores cloud se vuelven crisis cuando además no hay un plan de recuperación. En consecuencia, aunque el incidente sea “pequeño”, el impacto se multiplica por el tiempo muerto.
Alta disponibilidad y mantenimiento: evitar que un solo punto te apague todo
No todos los sistemas requieren HA compleja, sin embargo, casi todos requieren mantenimiento real: parches, reinicios controlados, limpieza de logs, y revisión de servicios críticos. Por lo tanto:
-
Programa mantenimiento recurrente.
-
Automatiza alertas y reinicios de servicios cuando aplique.
-
Separa ambientes si puedes (producción vs pruebas).
-
Documenta cambios (bitácora) y valida rollback.
Además, si el sistema es crítico (facturación, inventarios, contabilidad), evalúa escenarios de redundancia gradual: desde snapshots y replicación, hasta clúster o failover según presupuesto y criticidad.
Si tu operación depende de Windows y de acceso remoto estable, conviene evaluar servidores VPS Windows para sistemas administrativos con enfoque en desempeño y soporte para cargas reales.
Plan práctico en 3 pasos para estabilizar en 7–14 días
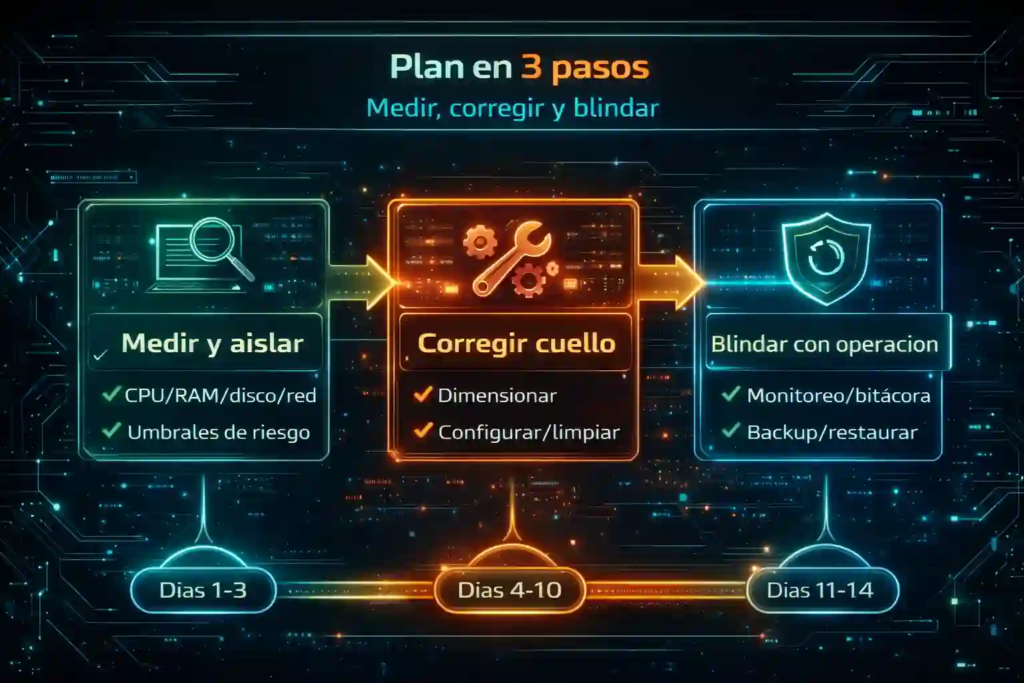
Para no quedarte en teoría, aplica este orden:
Paso 1: Medir y aislar (Días 1–3)
Primero instala/activa métricas, define umbrales y detecta el cuello dominante (CPU/RAM/disco/red). Además, registra “hora y operación” cuando ocurre el problema; esa correlación ahorra días.
2: Corregir el cuello (Días 4–10)
Luego corrige lo que manda: ajustar disco, ampliar RAM, revisar configuración de DB, limpiar jobs, o segmentar volúmenes. Sin embargo, cambia una cosa a la vez para saber qué arregló el problema.
Paso 3: Blindar con operación (Días 11–14)
Finalmente deja instalado el sistema de prevención: alertas, backups verificados, mantenimiento calendarizado, y bitácora. En consecuencia, reduces incidentes repetidos y vuelves predecible el desempeño.
Aquí el objetivo no es “cero problemas”, sino control: que los riesgos sean visibles y gestionables.
Errores comunes que disparan incidentes (y cómo evitarlos)
-
Crecer sin revisar disco: tarde o temprano explota. Por lo tanto, monitorea IOPS y espacio libre con margen.
-
Backups sin prueba de restore: es como no tener backup. Además, agenda pruebas.
-
Cambiar proveedor por precio: si no revisas garantías de recursos, te compras variabilidad. En consecuencia, compara por SLA y soporte.
-
No documentar cambios: cuando algo falla, nadie sabe qué tocó. Por lo tanto, bitácora simple pero constante.
Y sí, esto conecta con el tema central: caídas y lentitud en servidores cloud casi siempre son consecuencia de decisiones acumuladas, no de una “mala suerte” puntual.
Si necesitas revisar tu caso con un enfoque técnico y orientado a continuidad, puedes contactar al equipo y pedir una recomendación basada en métricas (no suposiciones).
Checklist final para operar estable mes a mes
Antes de cerrar, deja estas prácticas como rutina:
-
Revisión semanal de logs críticos.
-
Revisión de crecimiento de base y volúmenes.
-
Pruebas mensuales de restauración.
-
Revisión trimestral de dimensionamiento vs crecimiento.
-
Actualizaciones en ventanas controladas, con rollback definido.
Si haces esto, el servidor deja de ser “un gasto que da problemas” y se vuelve una plataforma operable. Y, sobre todo, el equipo deja de vivir apagando incendios.
Para aterrizarlo: caídas y lentitud en servidores cloud se reducen cuando conviertes la infraestructura en un proceso: medir, corregir, y blindar. Por lo tanto, si hoy tu sistema ya muestra señales, actúa antes de que el incidente te obligue a hacerlo en modo urgencia.
Si estás listo para estabilizar y escalar con una base sólida, revisa alternativas de servidores virtuales cloud VPS y compáralas contra tu carga real.
FAQ´s
1) ¿Cómo sé si la lentitud viene del servidor o del sistema?
Si el consumo de CPU/RAM/disco sube al mismo tiempo que la operación se vuelve lenta, el origen suele ser infraestructura. Si las métricas están estables, revisa aplicación y base de datos.
2) ¿Qué métrica es la más importante para un ERP en nube?
La latencia de disco y los IOPS suelen mandar. Después, RAM suficiente para evitar paginación y CPU para concurrencia.
3) ¿Cada cuánto debo revisar el rendimiento del servidor?
Idealmente a diario con alertas automáticas y, además, con una revisión semanal breve de tendencias (crecimiento, picos, errores).
4) ¿Por qué un servidor “se siente lento” solo en ciertos horarios?
Porque hay picos de usuarios, tareas programadas, respaldos o procesos de cierre. Por lo tanto, hay que correlacionar horario con métricas y eventos.
5) ¿Qué es RPO y RTO y por qué importan?
RPO es cuánta información puedes perder; RTO es cuánto tardas en volver. En sistemas críticos, ambos deben definirse y probarse.
6) ¿Los backups automáticos garantizan recuperación?
No necesariamente. Sin prueba de restauración, el backup puede fallar justo cuando más lo necesitas.
7) ¿Cuándo conviene migrar a un VPS Windows para sistemas administrativos?
Cuando dependes de aplicaciones Windows, escritorio remoto estable, o compatibilidad con componentes específicos. Además, conviene cuando el soporte y el rendimiento deben ser predecibles.
8) ¿Cómo puedo reducir caídas y lentitud en servidores cloud sin sobredimensionar?
Primero identifica el cuello con monitoreo, luego corrige el recurso dominante (disco/RAM/red), y finalmente implementa rutina de mantenimiento y continuidad.
9) ¿Qué ajustes simples suelen dar mejora inmediata?
Liberar espacio en disco, revisar tareas programadas, optimizar antivirus, separar volúmenes, y ajustar memoria/paginación de forma correcta.
10) ¿Qué debo pedirle a un proveedor para operar con estabilidad?
Recursos garantizados, especificación de almacenamiento e IOPS, soporte con tiempos claros, y herramientas de monitoreo/backup verificables.
2 Comments